

Gated Models
Gated models can be identified by a special symbol. If the model is “Gated”, you will find the necessary information on how to proceed. Example: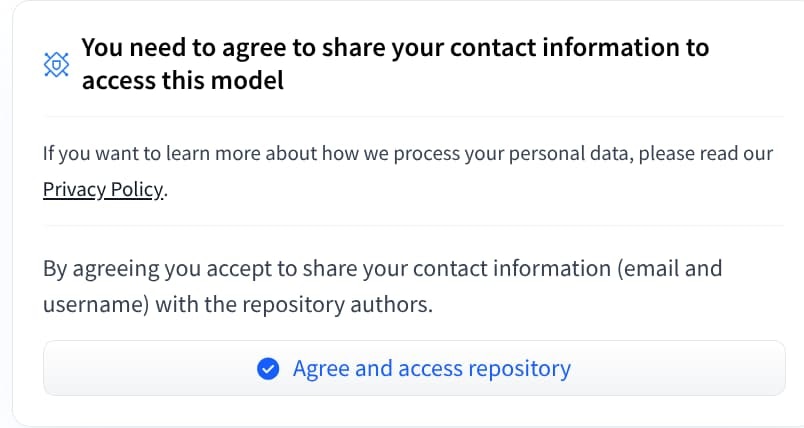
Creating a Hugging Face Access Token
To create a Hugging Face Access Token, follow these steps: We recommend you keep the “Save your Access Token” prompt open until you’ve securely stored your token as a FlexAI Secret, as you won’t be able to view it again.Storing a Hugging Face Access Token as a FlexAI Secret
To store your Hugging Face Access Token as a FlexAI Secret, follow these steps:- Using the FlexAI Console
- Using the FlexAI CLI
Creating a FlexAI Inference Endpoint
- Using the FlexAI Console
- Using the FlexAI CLI
The Launch Inference form
The Launch Inference form consists of a set of required and optional fields that you can use to customize your deployment.Required Fields
- Name: A unique name for your inference endpoint. This will be used to identify your endpoint in the FlexAI console. It must follow the FlexAI resource naming conventions.
- Hugging Face Model: The name of the model to deploy.
- Hugging Face Token: The name of the Secret you used to store your Hugging Face Access Token.
- Cluster: The cluster where the Training workload will run. It can be selected from a dropdown list of available clusters in your FlexAI account.
Form Values
Other fields
There are a few optional fields that you can use to customize your deployment:- API Key: A secret key that will be used to authenticate requests to your Inference endpoint. If left empty, a random API Key will be generated and displayed to you after you initiate the deployment process. Make sure to copy it and store it in a safe place, as you will not be able to see it again.
- vLLM Parameters: A set of arguments that will be passed to vLLM. You can use this to customize the behavior of the vLLM server, such as setting the maximum number of tokens to generate, the temperature, and other parameters.
FlexAI handles device selection for you, so the
--device vLLM parameter isn’t supported here — just leave it out.Starting the Inference Endpoint
After filling out the form, select the Submit button to start the Inference Endpoint deployment.You should get a confirmation window displaying the details of your Inference Endpoint, including the API Key that needs to be used to authenticate requests towards the endpoint.Checking the status of your Inference Endpoint
- Using the FlexAI Console
- Using the FlexAI CLI
After a few minutes, your Inference Endpoint should be up and running.Inference Endpoint DetailsYou can select the gear icon ⚙️ (labeled as Configure) in the
The Logs tabThe Logs tab provides you with real-time logs from your Inference Endpoint, allowing you to monitor its activity and troubleshoot any issues that may arise.You can use the Search bar input field to filter the logs by a specific keyword. This is useful to quickly find relevant information in the logs.
Actions field of the Inference Endpoint list row of your newly created Endpoint to open the details panel of the Inference Endpoint deployment.The Details tab will be opened by default, showing you all the relevant information about your Inference Endpoint.This tab provides you with detailed information about your Inference Endpoint, including:The Summary tabConfiguration
The Activity tabThe Activity tab provides you with a timeline of events related to your Inference Endpoint, including deployment status changes, scaling events, and more.
The Logs tabThe Logs tab provides you with real-time logs from your Inference Endpoint, allowing you to monitor its activity and troubleshoot any issues that may arise.You can use the Search bar input field to filter the logs by a specific keyword. This is useful to quickly find relevant information in the logs.
Managing your Inference Endpoint
- Using the FlexAI Console
- Using the FlexAI CLI
The Inference Endpoints table’s Actions column provides a set of actions that you can use to manage your Inference Endpoint:
- Configure: To access its Details panel.
- Pause: To temporarily stop the Inference Endpoint without deleting it.
- Delete: To permanently remove the Inference Endpoint.
- Resume: To restart a paused Inference Endpoint.