The name of the Inference Endpoint to create.
Examples
-
mixtral_8x7b
Creates an Inference Endpoint from a model hosted by Hugging Face. The target model must be part of the vLLM supported models list found here 🔗 .
A Secret containing a Hugging Face Access Token 🔗 is required in order to serve an Inference Endpoint. It will be passed to the --hf-token-secret flag below:
flexai inference serve <inference_endpoint_name> [ --accels <number_of_accelerators> ] [ --api-key-secret <name_of_secret_containing_the_api_key> ] [ --device-arch <device_architecture> ] [ --hf-token-secret <name_of_secret_containing_the_hugging_face_token> ] [ --max-replicas <max_replicas> ] [ --min-replicas <min_replicas> ] [ --no-queuing ] ( -- --model=<model_name> [<vLLM_arguments>...] )<vLLM_arguments> refers to a list of vLLM Engine Arguments can be passed to the command after the End-of-options marker (--). The list of supported arguments can be found in the next section.
The name of the Inference Endpoint to create.
mixtral_8x7b The End-of-options marker.
Everything after this marker is passed to the vLLM Engine.
-- The name of the model to use for the Inference Endpoint.
Visit the vLLM supported models list found here 🔗 to see the list of supported models.
model_name=mistralai/Mixtral-8x7B-v0.1 vLLM Engine Arguments that can be passed after the End-of-options marker (--).
Note: The --device argument is not supported: FlexAI handles the device selection tasks.
1 Number of accelerators to use for the workload.
--accels 4 nvidia nvidia--device-arch nvidia The name of a FlexAI Secret containing the API key you want to set to protect the Inference Endpoint.
If not provided:
<inference_endpoint_name>-api-key containing the auto-generated API key will be created.--api-key-secret ENDPOINT_ACCESS_TOKEN The maximum number of replicas to use for the Inference Endpoint.
--max-replicas 4 The minimum number of replicas to use for the Inference Endpoint.
--min-replicas 4 Disable queuing for the Inference Endpoint.
This means that if there are not enough resources available in the cluster, the request will be rejected immediately instead of being queued.
--no-queuing The name of the FlexAI Secret containing the Hugging Face token that will be used to access the model.
You can visit the Hugging Face Hub 🔗 to create a token.
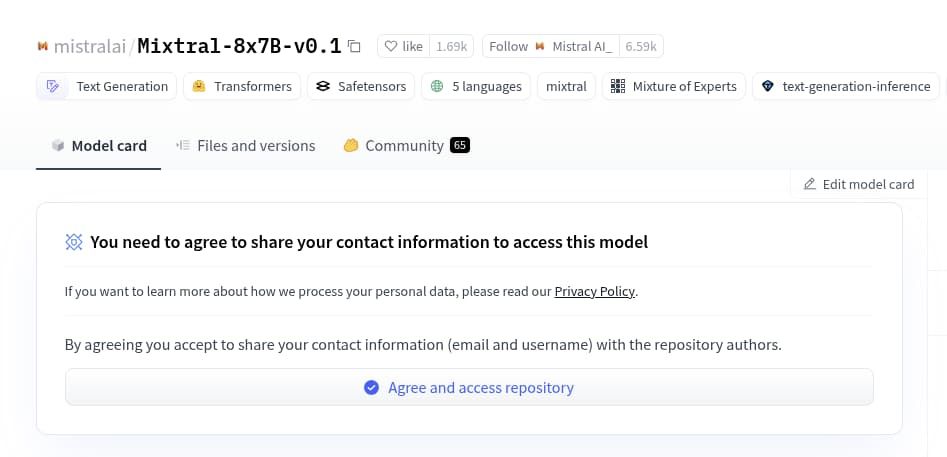
--hf-token-secret HF_TOKEN_PROD Keep in mind that some models are “Gated”, meaning that you need to go through a process of agreeing to their license agreement, privacy policy, or similar before you can use them.
You can visit the model’s page on the Hugging Face Hub to see if it is marked as “Gated”. Gated models can be identified by this symbol:  . If the model is “Gated”, you will find the necessary information on how to proceed. Example:
. If the model is “Gated”, you will find the necessary information on how to proceed. Example:
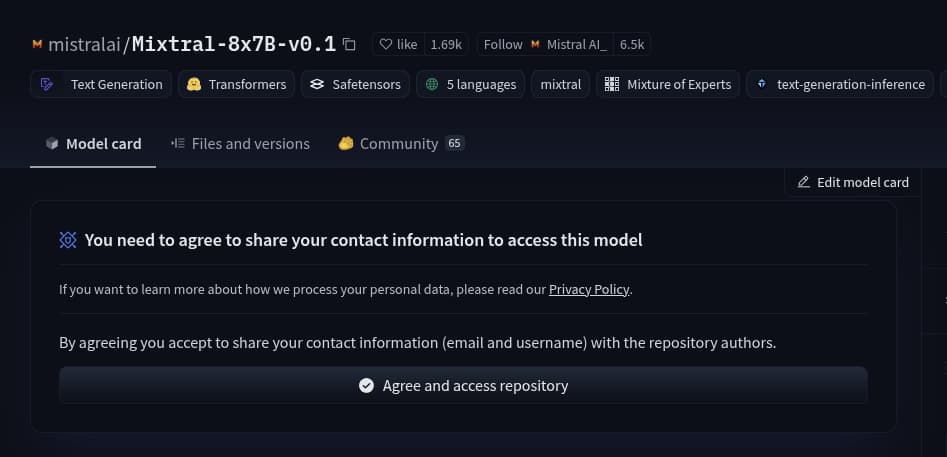
If you have already gone through the process, you will find a badge on the model’s page indicating that you have access to the model. Example: