Deploying an Inference Endpoint for a private model
The process of Deploying an Inference Endpoint for a model on FlexAI is straightforward and can even be as simple as entering the name of the model you want to deploy.
However, if you want to deploy a private model from Hugging Face or a model that requires you to agree to their terms & conditions, you will need to provide your a Hugging Face Access Token that you can create via the Hugging Face website.
This quickstart tutorial guides you through the generation of a Hugging Face Access token to create an Inference Endpoint for the facebook/opt-125m model hosted on Hugging Face 🔗.
-
Create a Hugging Face Access Token via the Hugging Face website 🔗.
-
Store your Hugging Face Access Token using the FlexAI Secret Manager.
Terminal window flexai secret create hf-access-token -
Create an Inference endpoint for the model you want to deploy.
Terminal window flexai inference serve fbopt125 \--hf-token-secret hf-access-token \-- --model=facebook/opt-125m -
Store the API Key you’re prompted with. You will need it to authenticate your requests to the Inference Endpoint.
flexai inference serve fbopt125... Inference "fbopt125" started successfullyHere is your API Key. Please store it safely: 0ad394db-8dba-4395-84d9-c0db1b1be0a8. You can reference it with the name: fbopt125-api-key -
Run
flexai inference listto follow the status of your Inference Endpoint and get its URL.Terminal window flexai inference listflexai inference list NAME │ STATUS │ AGE │ ENDPOINT───────────┼──────────────────┼─────┼──────────────────────────────────────────────────────────────────────────────────fbopt125 │ starting │ 12s │ https://inference-e0ed242b-dbd3-423e-b525-76beac222d44-d41b1b44.platform.flex.ai -
Use the Inference Endpoint URL to make requests to your model.
Terminal window curl -X POST https://inference-e0ed242b-dbd3-423e-b525-76beac222d44-d41b1b44.platform.flex.ai/v1/completions \-H "Content-Type: application/json" \-H "Authorization: Bearer 0ad394db-8dba-4395-84d9-c0db1b1be0a8" \-d '{"model": "facebook/opt-125m","prompt": "Why do koalas eat eucalyptus leaves?","max_tokens": 240,"temperature": 0}'Notice how you can add any additional parameters to the request, such as
temperature,top_p,top_k, etc. This allows you to customize the behavior of the model during inference.curl response (rendered as JSON by using jq) {"id": "cmpl-9c3d178b-62d6-4459-b6f8-6240e7707073","object": "text_completion","created": 1755973968,"model": "facebook/opt-125m","choices": [{"index": 0,"text": "\n\nThe koalas eat eucalyptus leaves, which are the most common species of eucalyptus. They are the most common species of eucalyptus, and they are the most common species of eucalyptus. They are the most common species of eucalyptus, and they are the most common species of eucalyptus. They are the most common species of eucalyptus, and they are the most common species of eucalyptus. They are the most common species of eucalyptus, and they are the most common species of eucalyptus. They are the most common species of eucalyptus, and they are the most common species of eucalyptus. They are the most common species of eucalyptus, and they are the most common species of eucalyptus. They are the most common species of eucalyptus, and they are the most common species of eucalyptus. They are the most common species of eucalyptus, and they are the most common species of eucaly","logprobs": null,"finish_reason": "length","stop_reason": null,"prompt_logprobs": null}],"usage": {"prompt_tokens": 14,"total_tokens": 254,"completion_tokens": 240,"prompt_tokens_details": null},"kv_transfer_params": null}
These steps remain the same for any private model you want to deploy using FlexAI. You just need to replace the model name in the --model argument with the name of the model you want to deploy.
Inference Playground
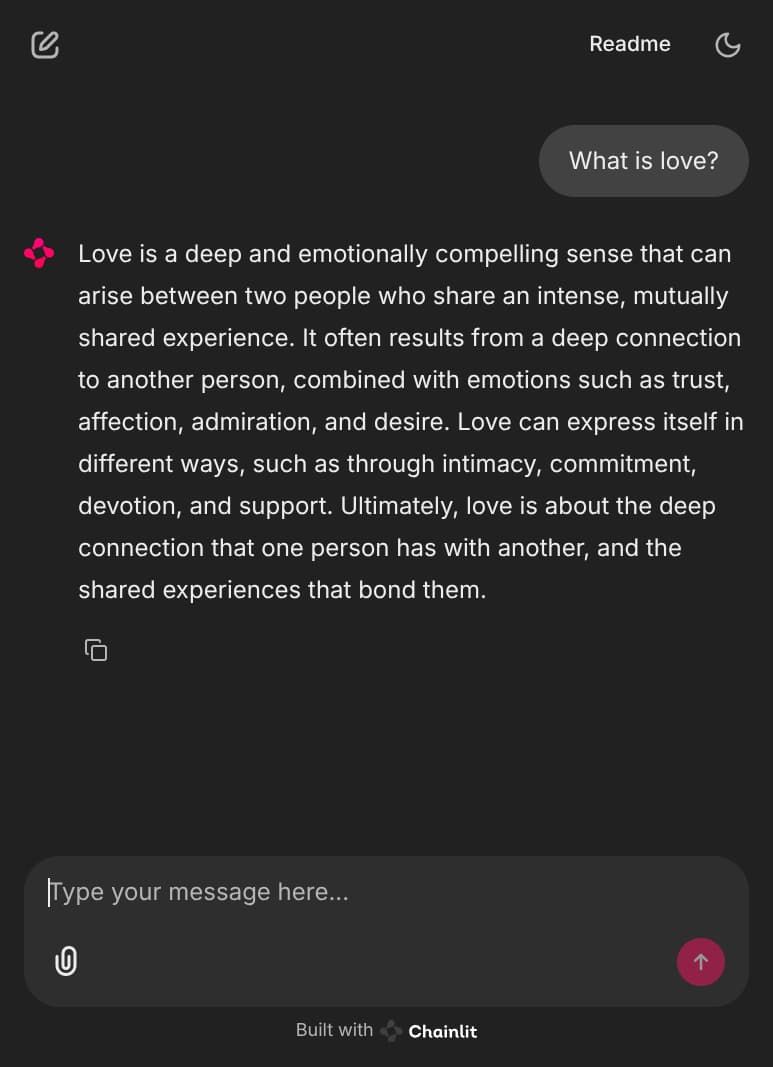
Section titled “Inference Playground”After a successful deployment, you can run the flexai inference inspect command to get the URL for your FlexAI hosted “Playground” environment. This is a https://chainlit.io/ 🔗 based UI that allows you to interact with your deployed model in a user-friendly way.
flexai inference inspect fbopt125metadata: name: fbopt125 id: ... creatorUserID: ... ownerOrgID: ...config: device: nvidia accelerator: 1 apiKeySecretName: fbopt125-api-key endpointUrl: https://inference-e0ed242b-dbd3-423e-b525-76beac222d44-d41b1b44.platform.flex.ai playgroundUrl: https://inference-e0ed242b-dbd3-423e-b525-76beac222d44-playgro-d41b1b44.platform.flex.ai // ...When you follow the playgroundUrl, you will get a Chainlit UI where you can interact with your deployed model. You can use this UI to test your model with various types of inputs (images, videos, files, or just text, depending on the model).