Deploying an Inference Endpoint
The process of Deploying an Inference Endpoint for a model on FlexAI is straightforward and can even be as simple as entering the name of the model you want to deploy.
This quickstart tutorial will walk you through the steps to deploy an Inference Endpoint for the TinyLlama/TinyLlama-1.1B-Chat-v1.0 model hosted on Hugging Face 🔗.
-
Create an Inference endpoint for the model you want to deploy.
Terminal window flexai inference serve tiny-llama \--hf-token-secret hf-access-token \-- --model=TinyLlama/TinyLlama-1.1B-Chat-v1.0 -
Store the API Key you’re prompted with. You will need it to authenticate your requests to the Inference Endpoint.
flexai inference serve tiny-llama... Inference "tiny-llama" started successfullyHere is your API Key. Please store it safely: 0ad394db-8dba-4395-84d9-c0db1b1be0a8. You can reference it with the name: tiny-llama-api-key -
Run
flexai inference listto follow the status of your Inference Endpoint and get its URL.Terminal window flexai inference listflexai inference list NAME │ STATUS │ AGE │ ENDPOINT───────────┼──────────────────┼─────┼──────────────────────────────────────────────────────────────────────────────────tiny-llama │ starting │ 32s │ https://inference-e0ed242b-dbd3-423e-b525-76beac222d44-d41b1b44.platform.flex.ai -
Use the Inference Endpoint URL to make requests to your model.
Terminal window curl -X POST https://inference-e0ed242b-dbd3-423e-b525-76beac222d44-d41b1b44.platform.flex.ai/v1/completions \-H "Content-Type: application/json" \-H "Authorization: Bearer 0ad394db-8dba-4395-84d9-c0db1b1be0a8" \-d '{"model": "TinyLlama/TinyLlama-1.1B-Chat-v1.0","prompt": "Why do koalas eat eucalyptus leaves?","max_tokens": 240,}'curl response (rendered as JSON by using jq) {"id": "cmpl-6bfdc141-4f40-45b0-a241-b9fc9a42b8da","object": "text_completion","created": 1755973474,"model": "TinyLlama/TinyLlama-1.1B-Chat-v1.0","choices": [{"index": 0,"text": " Eucalyptus is a plant that is specific to tropical regions around the world. The leaves of the eucalyptus are consumed by koals as a source of food. Emus are carnivorous and eat meat and grasses that are not leafy. Koalas don’t have much muscle mass, so they rely on their brains and handlers to eat leaves. Koalas are mainly scavengers and won’t eat fruit, but they can occasionally swallow large parts of bark if they are hungry and their food source is present. They’ve been known to swallow full baskets of fruit in some cases. Emus are carnivorous, meaning they have sharp teeth and a powerful jaw, so they do consume meat. Other animals eat eucalyptus leaves, but emus are the only known diurnal carnivores (carnivores that hunt at dawn or dusk for their food). is found in Australia’s biggest land animal, the koala. How do koalas depend on eucalyptus leaves as a food source? The eucal","logprobs": null,"finish_reason": "length","stop_reason": null,"prompt_logprobs": null}],"usage": {"prompt_tokens": 14,"total_tokens": 254,"completion_tokens": 240,"prompt_tokens_details": null},"kv_transfer_params": null} -
Enjoy your AI-powered application!
Inference Playground
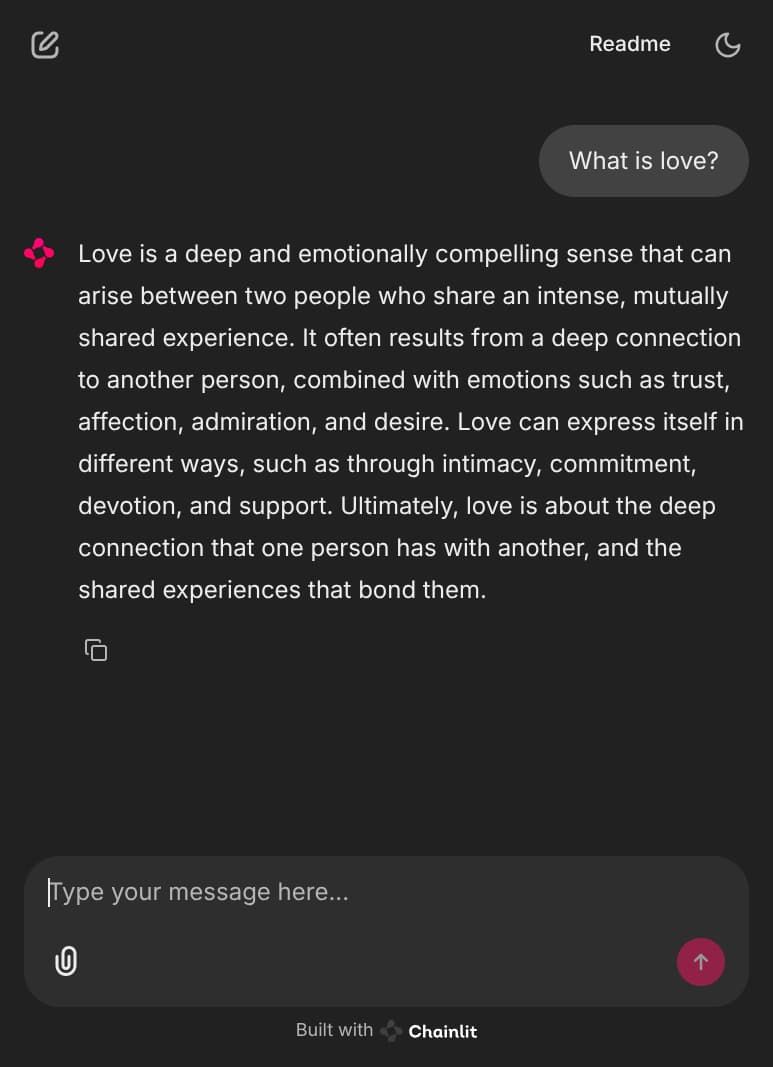
Section titled “Inference Playground”After a successful deployment, you can run the flexai inference inspect command to get the URL for your FlexAI hosted “Playground” environment. This is a https://chainlit.io/ 🔗 based UI that allows you to interact with your deployed model in a user-friendly way.
flexai inference inspect tiny-llamametadata: name: tiny-llama id: ... creatorUserID: ... ownerOrgID: ...config: device: nvidia accelerator: 1 apiKeySecretName: tiny-llama-api-key endpointUrl: https://inference-e0ed242b-dbd3-423e-b525-76beac222d44-d41b1b44.platform.flex.ai playgroundUrl: https://inference-e0ed242b-dbd3-423e-b525-76beac222d44-playgro-d41b1b44.platform.flex.ai // ...When you follow the playgroundUrl, you will get a Chainlit UI where you can interact with your deployed model. You can use this UI to test your model with various types of inputs (images, videos, files, or just text, depending on the model).